Employee Exit Data Cleaning
You can find the full Jupyter Notebook on GitHub here.
In this project, we will clean and analyze employee exit survey data from the Department of Education, Training, and Employment (DETE) as well as the Technical and Further Education Institute (TAFE) in Australia. The original DETE data can be found here. The TAFE data is no longer available.
Goals
The stakeholders for this project want to know the following:
- Are employees who only worked for the institutes for a short period of time resigning due to some kind of dissatisfaction? What about employees who have been there longer?
- Are younger employees resigning due to some kind of dissatisfaction? What about older employees?
This is predominantly a data cleaning project. As such, we will focus the narrative more on how we clean the data to prepare it for analysis.
Data Dictionary
Some columns we will use from the DETE data:
ID: An id used to identify the participant of the surveySeparationType: The reason why the person’s employment endedCease Date: The year or month the person’s employment endedDETE Start Date: The year the person began employment with the DETE
Some columns we will use from the TAFE data:
Record ID: An id used to identify the participant of the surveyReason for ceasing employment: The reason why the person’s employment endedLengthofServiceOverall. Overall Length of Service at Institute (in years): The length of the person’s employment (in years)
Exploring the Data
We read in the data using pandas and explore it quickly using df.head() and df.info().
The DETE survey contains 56 columns and 822 rows. A number of columns has missing data we might need to clean. Most data types are objects or boolean, except ID which is an integer.
The TAFE survey contains 72 columns and 702 rows. The majority of columns have some missing data. Most data types are objects.
We then use df_series.isnull().sum() and df_series.value_counts() to investigate the missing values and distributions. This gives us some initial ideas about how and what data we will need to clean.
The DETE survey has 0 missing IDs or Separation Types, which is good because those are directly related to our goals.
Separation Type has 9 unique values. Both ‘Resignation-Other reasons’ and ‘Other’ might be able to be combined together.
Missing data for DETE Start Date is listed as ‘Not Stated.’ Other dates are all four digit years.
Missing data for DETE Cease Date is listed as ‘Not Stated.’ There are two ways dates are stored for this column, as 4 digit years and mm/yyyy.
The TAFE survey:
- Record ID: no missing values
- Reason for ceasing employment: 1 null value, 6 other unique values
- Length of Service Overall: 106 null values. 7 other unique values, which are ranges of service
Identify Missing Values and Drop Unnecessary Columns
We will go change what we did above to read ‘Not Stated’ as NANs in the DETE survey.
Then we will drop some columns from each dataframe that we won’t use in our analysis to make the dataframes easier to work with. To do this we use df.drop() with the parameter axis=1 to drop the columns.
Clean Column Names
Each dataframe contains many of the same columns but the column names are different. We will want to combine columns later, so we first need to standardize the column names.
For the DETE survey, we should:
- make all column names lowercase
- remove any trailing whitespace
- replace spaces with _
Since these are standardized changes, we will can use vectorized string methods to do this at once. We accomplish this with a single line:
dete_survey_updated.columns = dete_survey_updated.columns.str.lower().str.strip().str.replace(' ', '_')
We also want to rename some of the TAFE survey colum names. We will use the DataFrame.rename() method to do this.
col_rename_dict = {'Record ID': 'id',
'CESSATION YEAR': 'cease_date',
'Reason for ceasing employment': 'separationtype',
'Gender. What is your Gender?': 'gender',
'CurrentAge. Current Age': 'age',
'Employment Type. Employment Type': 'employment_status',
'Classification. Classification': 'position',
'LengthofServiceOverall. Overall Length of Service at Institute (in years)': 'institute_service',
'LengthofServiceCurrent. Length of Service at current workplace (in years)': 'role_service'}
tafe_survey_updated.rename(columns=col_rename_dict,inplace=True)
Filter the Data
Now that we have renamed the columns we will use for the analysis, we will remove some of the data we will not use. For this project, we will only look at the employees who resigned. We select only the data where the separation type indicates a resignation
dete_resignations = dete_survey_updated[(dete_survey_updated['separationtype'] == 'Resignation-Other reasons')
Verify the Data
Before we start cleaning and manipulating the rest of our data, we should verify that the data does not contain any major inconsistencies. We will focus on verifying the cease_date and dete_start_date columns. We should check that the cease_data is after the dete_start date. It is also unlikely that the start date was before the year 1940.
When we look at the format of the dates using df_series.value_counts() we see there are two main formats for dates. We extract just the year using:
dete_resignations['cease_year'] = dete_resignations['cease_date'].str[-4:].astype(float)
We then check the years of service and see that neither dataset has negative years of service, so we conclude the dates are reasonable for our purposes.
Identify Dissatisfied Employees
We now want to identify employees who resigned because they were dissatisfied. There are multiple, different columns in each survey that indicate job dissatisfaction. We will use these to create a new column called dissatisfied.
We want to update these values to Boolean for easily manipulation and analysis. The following function will help:
def update_vals(x):
if x == pd.isnull(x):
return np.nan
elif x == '-':
return False
else:
return True
And we apply this function to the TAFE dataset as follows
factors = ['Contributing Factors. Dissatisfaction','Contributing Factors. Job Dissatisfaction']
tafe_map = tafe_resignations[factors].applymap(update_vals)
tafe_resignations['dissatisfied'] = tafe_map.any(axis=1, skipna=False).copy()
And do something similar for the DETE dataset.
Combine the Data
Now we are ready to combine our data. We will want to aggreate our data according to the institute_service column.
First, we should add a column to each dataset helping us to distinguish between the two. Then we combine the data using pd.concat.
Clean the Service Column
The institute_service column contains data in a few different formats. We will convert these formats and numbers into a few different categories for analysis. We will use the following definitions
- New: Less than 3 years at a company
- Experienced: 3-6 years at a company
- Established: 7-10 years at a company
- Veteran: 11 or more years at a company
We need to use a regular expression to extract the years of service
pattern = r"(\d+)"
combined['institute_service'] = (combined['institute_service'].astype('str').str.extract(pattern).astype(float)
Then we map the years of service to these definitions as
def map_career_state(value):
'''Maps value to a corresponding service category'''
if pd.isnull(value):
return np.nan
elif value < 3:
return 'New'
elif (value >=3 and value <=6):
return 'Experienced'
elif (value >=7 and value <=10):
return 'Established'
else:
return 'Veteran'
combined['service_cat'] = combined['institute_service'].apply(map_career_state)
Perform Initial Analysis
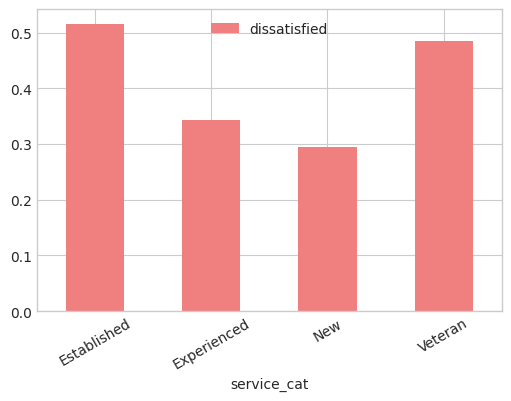
We will end the blog summary with a bar chart showing the percent dissatisfied employees by category of service.